
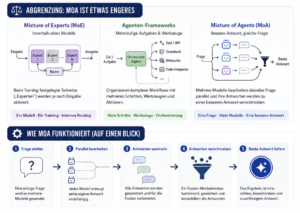
Mixture of Agents (MoA). Im Mittelpunkt steht die Aussage, dass MoA keine neue Modellarchitektur, sondern eine Methode zur Qualitätssteigerung von KI-Antworten ist. Mehrere grosse Sprachmodelle bearbeiten dieselbe Eingabe unabhängig voneinander. Anschliessend werden ihre Antworten bewertet und zu einer gemeinsamen, qualitativ besseren Antwort zusammengeführt.
Was ist Mixture of Agents?
Die meisten Menschen suchen heute nach dem besten KI-Modell. GPT-4, Claude, Gemini oder Llama. Die Annahme dahinter ist einfach: Das stärkste Modell liefert automatisch die besten Antworten.
Doch genau diese Annahme wird zunehmend infrage gestellt. Mit Mixture of Agents (MoA) entsteht ein neuer Ansatz. Dabei geht es nicht darum, ein noch grösseres Modell zu entwickeln. Stattdessen arbeiten mehrere bestehende Modelle gemeinsam an derselben Aufgabe.
Das eigentliche Problem ist also nicht, welches Modell am intelligentesten ist. Sondern wie verschiedene Modelle sinnvoll zusammenarbeiten. Mixture of Agents, kurz MoA, ist aber keine neue Modellarchitektur, sondern eine Methode.
Mehrere Sprachmodelle erhalten dieselbe Frage. Jedes entwickelt unabhängig eine eigene Antwort. Anschliessend werden diese Antworten miteinander verglichen und zu einer besseren Gesamtlösung kombiniert.
Die Idee stammt aus dem Paper “Mixture-of-Agents Enhances Large Language Model Capabilities” von Together AI, das als Spotlight-Paper auf der ICLR 2025 vorgestellt wurde.
Das Besondere daran: Es braucht kein zusätzliches Training. Statt ein neues Modell zu entwickeln, nutzt MoA vorhandene Modelle intelligenter.
Die Grundidee lässt sich einfach zusammenfassen:
Ein gut koordiniertes Team kann besser arbeiten als der stärkste Einzelspieler.
So funktioniert MoA
Der Ablauf besteht aus drei Schritten. Zuerst beantworten mehrere Modelle dieselbe Frage unabhängig voneinander. Dadurch entstehen unterschiedliche Lösungsansätze und Perspektiven. Danach lesen weitere Modelle diese Antworten. Sie erkennen Stärken, Schwächen oder Widersprüche und entwickeln daraus bessere Versionen.
Zum Schluss übernimmt ein sogenannter Aggregator. Er erstellt aus allen Antworten eine gemeinsame finale Lösung. Wichtig ist dabei: Es handelt sich nicht um eine Abstimmung. Die beste Antwort gewinnt nicht, weil sie am häufigsten vorkommt. Vielmehr kombiniert der Aggregator die stärksten Argumente zu einer neuen Antwort.
Der Aggregator ist das eigentliche Gehirn
Viele stellen sich MoA wie einen Mehrheitsentscheid vor.
Genau das wäre jedoch zu einfach.
Ein schlechter Aggregator würde lediglich mehrere Antworten mitteln. Das Ergebnis wäre oft nur Durchschnitt.
Ein guter Aggregator erkennt dagegen,
- welche Antworten besonders überzeugend sind,
- welche Aussagen sich widersprechen,
- welche Argumente sich ergänzen,
- und wie daraus eine bessere Gesamtlösung entsteht.
Der entscheidende Unterschied liegt also nicht in der Anzahl der Modelle, sondern in der Qualität ihrer Zusammenarbeit.
Warum funktioniert das überhaupt?
Die spannendste Erkenntnis der Forschung ist überraschend einfach. Sprachmodelle werden besser, wenn sie die Antworten anderer Modelle sehen. Selbst dann, wenn diese Antworten nicht perfekt sind. Andere Lösungswege helfen dabei, eigene Fehler zu erkennen, blinde Flecken zu vermeiden und bessere Schlussfolgerungen zu ziehen.
Die Forschenden nennen diesen Effekt Collaborativeness. Menschen kennen dieses Prinzip längst aus der Teamarbeit. Gute Ideen entstehen oft nicht allein, sondern im Austausch mit anderen.
Sakana Fugu – der Pufferfisch für MOA
Im ursprünglichen Paper erreichte ein Verbund aus Open-Source-Modellen 65,1 Prozent auf AlpacaEval 2.0 und übertraf damit GPT-4 Omni mit 57,5 Prozent. Die eigentliche Botschaft steckt jedoch nicht in der Zahl. Sakana AI geht hier noch einen Schritt weiter. Das Unternehmen wurde unter anderem von Llion Jones, einem Mitautor von Attention Is All You Need, gegründet.
Ihr System Fugu ersetzt die feste Architektur von MoA durch einen intelligenten Dirigenten.
Dieser entscheidet für jede einzelne Aufgabe,
- welche Modelle eingesetzt werden,
- welche Rolle sie übernehmen,
- und wie sie zusammenarbeiten.
Mal braucht es mehr kreative Denker, mal stärkere Prüfer oder spezialisierte Experten. Das Team entsteht also jedes Mal neu.
Genau deshalb trägt das System den Namen Fugu, der japanische Pufferfisch. Er bläht sich nur dann auf, wenn es nötig ist. Genauso aktiviert Fugu nur die zusätzliche Intelligenz, die für die jeweilige Aufgabe wirklich gebraucht wird.
MoA bringt einige klare Stärken mit. Mehrere Modelle liefern unterschiedliche Perspektiven und machen das Ergebnis robuster. Gleichzeitig sinkt die Abhängigkeit von einem einzelnen Anbieter. Das wurde spätestens 2026 deutlich, als Exportbeschränkungen einzelne Modelle kurzfristig unzugänglich machten. Wer verschiedene Modelle orchestriert, verteilt dieses Risiko.
Natürlich hat der Ansatz auch Nachteile. Mehrere Modelle benötigen mehr Rechenleistung und mehr Zeit. Erst wenn alle Antworten vorliegen, kann der Aggregator die finale Antwort erzeugen. Für Echtzeit-Anwendungen ist das nicht immer geeignet. Zudem diskutiert die Forschung derzeit eine wichtige Frage: Braucht es möglichst unterschiedliche Modelle oder reicht ein besonders guter Aggregator?
Vieles deutet darauf hin, dass künftig vor allem die Qualität der Orchestrierung entscheidend sein wird.
Was bedeutet das für Unternehmen?
Über Jahre lautete die wichtigste Frage: Welches Modell ist das beste? Diese Frage verliert langsam an Bedeutung.
Die strategisch wichtigere Frage lautet künftig: Wie bringe ich verschiedene Modelle dazu, gemeinsam bessere Ergebnisse zu liefern? Der Wettbewerb verschiebt sich, und nicht das grösste Modell gewinnt, sondern das am besten koordinierte Team. Für Unternehmen bedeutet das, dass Orchestrierung zu einer neuen Kernkompetenz wird.t.
Die wichtigsten Punkte verdichtet
- Mixture of Agents ist eine Laufzeit-Methode, die mehrere Modelle in Schichten zusammenarbeiten lässt, ohne neues Training, eingeführt von Together AI an der ICLR 2025.
- Die Architektur kennt zwei Rollen: Proposer erzeugen diverse Erstantworten, ein Aggregator verschmilzt sie zur finalen Antwort.
- Der Kern ist die Collaborativeness: Modelle werden besser, wenn sie fremde Antworten als Referenz sehen, selbst schwächere.
- Ein reiner Open-Source-Verbund schlug GPT-4 Omni auf AlpacaEval 2.0, ein Beleg, dass Koordination Grösse schlagen kann.
- Sakana Fugu treibt das Prinzip weiter: ein gelernter Pufferfisch-Dirigent stellt pro Aufgabe ein Team zusammen und ruft sich rekursiv selbst auf.
- Die Grenzen sind Latenz und ein offener Forschungsstreit darüber, ob Diversität oder Aggregator-Qualität den Ausschlag gibt.
- Der Trend verschiebt den Engpass von Modellgrösse zu Koordinationslogik. Orchestrierung wird zur strategischen Ebene.
Und darum bin ich nach wie vor überzeugt: Die Zukunft gehört nicht mehr dem Tippen und Klicken und auch nicht dem grössten Einzelmodell, sondern dem gemAInsamen Arbeiten mit orchestrierten Systemen, in denen der Mensch entscheidet, welche Intelligenz für welche Aufgabe zusammenkommt. Also wenn Du reden willst, und wenn Du mit mir zusammenarbeiten willst: melde Dich gerne www.rogerbasler.ch
Quelle
Sakana AI. (2026). Sakana Fugu: A multi-agent orchestration system as a foundation model [Technical report]. arXiv. https://arxiv.org/html/2606.21228v1